
“Jarvis, you up?”
For you, sir, always.
Tony Stark then goes on to give a series of commands to check and access his uber-cool Ironman suit.
Jarvis even warns Mr. Stark that terabytes of calculations need to be done before an actual flight, only to be met with Tony’s cocky reply – “Jarvis! Sometimes you gotta run before you can walk.”
Looks like a normal conversation with a personal assistant, doesn’t it?
Except that Jarvis isn’t a human being but a smart AI assistant capable of holding seamless conversations and available at your service, always.
If you want to reconstruct Jarvis in reality, Natural Language Processing (NLP) would be the first technology you would consider. A subfield of AI, NLP is a machine’s ability to understand human language in speech or text thereby narrowing the communication gap between man and machine.
With enough virtual assistants like Siri and Cortana in the market already, are we ready to pull off a Jarvis? Let’s see how NLP was used over the decades and where it’s future course lies.
Where did it all start?
In his paper “Computing Machinery and Intelligence” published in 1950, Alan Turing poses a revolutionary question – “Can machines think?”. Though the 1940s saw glimpses of NLP in machine translation, the now-so-popular “Turing test” (also known as the imitation game), opened the possibilities of machines trying to comprehend the complex field of linguistics.
To fulfill Turing’s criteria, a machine has to understand a human’s natural language in order to frame an intelligent human-like response.
Many attempts were then initiated to pass the Turing test. ELIZA, SHRDLU, and PARRY were all precursors of interest in NLP. After a brief lull in NLP research, due to a halt in funding for NLP research by the Automatic Language Processing Advisory Committee (ALPAC) formed by the US government, natural language processing acquired a new dimension with the “statistical revolution” of the 1980s.
To know the detailed history of NLP up to the 1990s, I suggest you go through an article by Dr. Hancox and another on dataversity.
What we are more interested in here is the bloom in NLP since the 1980s, when application of statistical methods grew significantly. It is important to note that NLP may not necessarily be the backbone of all the technologies described in this post, but they do involve NLP tasks to a certain extent.
The Era of Machine Translation
You could call machine translation as the genesis of teaching machines our natural language. The ease with which Google Translate works now has a long history dating back to the 1930s when patents began to be filed for translating machines.
Translations saw the light of day in 1954 when the Georgetown-IBM experiment was conducted by scientists to automatically translate more than 60 Russian sentences into English. In the late ’80s, Statistical Machine Translation (SMT) stole the limelight off rule-based translation when researchers at IBM (Candide Project) worked on a large corpus of French and English texts found in the Canadian parliamentary debates reports, letting go of linguistic rules and calculated probabilities instead.
Meanwhile, the corpus-based translation or Example-based machine translation (EBMT) was also scrutinized by groups of researchers in Japan who worked with previously translated examples or corpora to translate new words.
By 1994, Systran’s machine translation was available in a few CompuServe chat forums and in 1997 one of the oldest online translators – BabelFish was launched by AltaVista (later taken over by Yahoo) that could do 36 pairs of language translation on a web browser.
In 2001 syntax-based machine translation (translating syntactic units instead of words) was proposed, followed by phrase-based machine translation established between 2003 and 2005 that was later used to propel Google translate in 2006. Bing and Yandex launched their translators soon after in 2009 and 2011 respectively.
While silent research was carried out on using Recurrent Neural networks for MT, a decade since its inception, Google Translate ushered a radical leap in commercial-scale translation by employing neural networks that were trained on very large datasets. Termed as the Google Neural Machine Translation system(GNMT), the engine behind Google Translate could confidently handle close to 10,000 language pairs in 2016.
Ever since NMT came in the picture, hybrid approaches to translation are being experimented with to close the gaps in NMT with the benefits of phrasal or rule-based machine translation.
Does this mail scream “SPAM”?
The widespread use of E-mail as a form of digital communication to date comes with the classic problem of ham and spam. While IP blacklisting and email header inspection were initially used to identify spam, these methods when individually deployed were easily bypassed, thanks to IP and email spoofing.
Thus arose the need for email content to be analyzed along with non-textual elements, signaling the entry of NLP to spot spam. In 1998, the Bayesian approach to filtering junk e-Mail was proposed followed by a commercially viable work on the same lines by Paul Graham (A Plan for Spam) in 2002. The Bayesian method, one of the earliest methods of statistical NLP, differed from usual text-based filters by its ability to automatically learn new words seen in probable spams and hence classified mails better with its expanding vocabulary.

A word cloud of common words in spam
Bayesian filters got better by scrutinizing mail header content, pairs of words, and phrases resulting in lower false positives and higher accuracy of spam identification and were implemented in many modern email clients.
To further decrease the number of spams, Google announced in 2015 its usage of neural networks in its spam filters bringing the spam rate down to 0.1%.
“Hey, Siri! What’s the weather like today?”
An important movement in Natural Language Processing is IBM’s Shoebox (1962) and later Harpy in the 1970s that stand as precursors for digital speech recognition. By the mid-1980s, the Hidden Markov Method (HMM) was found to be highly useful in modeling speech.
Though considerable success was shown by IBM’s Watson winning Jeopardy! In 2011, intelligent virtual assistants as we know them today gathered momentum when Apple rolled out SIRI on iPhone 4S in the same year. And yes, Raj finally found the woman he can talk to in the 2012 Big Bang Theory series 🙂

Google Assistant (initially called Google Now) and Microsoft’s Cortana followed suite with Amazon introducing Alexa in 2014 sitting inside a smart speaker – Echo.
To view a complete timeline of voice assistants, check out this cool infographic by voicebot.ai.
AI voice assistants quickly found their way into a host of apps and devices, the google home for example, and Amazon selling over 100 million Alexa-enabled devices by Jan 2019.
Chatterboxes to the rescue
A close relative of virtual assistants is the AI-powered chatbots that carry out human-like conversations on messaging apps and online chats.
The idea of machines trying to converse with humans was set off by chatbots like ELIZA(1966), PARRY (1972) and later by Jabberwacky (1988) that even tried to crack jokes. With advancements in ML and Natural Language Processing, AI chatbots can now hold seamless conversations with users by understanding user intent and providing relevant inputs.
China-based company WeChat built a smart chatbot in 2009 but AI chatbots gained prominence in 2016 when Facebook opened it’s messenger platform to build chatbots and within 2 years 300,000 active chatbots were developed on the platform.
Customer service has been immensely boosted by AI chatbots due to their 24/7 availability, the capability to address customer complaints and resolve simple questions. AI chatbots powered by NLP, are ready to take on 15% of all customer service interactions worldwide by 2021.
Sniffing sentiments behind statements
Going beyond mere text analysis, efforts were taken to identify the feelings behind highly unstructured content and their contextual significance. Early research on classifying movie reviews found on the web as positive or negative using ML techniques (Naive Bayes, SVM, and MaxEnt) was done by Bo Pang et al in 2002.
A subsequent paper in 2004 by Bo Pang and Lillian Lee, discussed the radical effects of bringing “subjectivity” (how relevant is a particular word in voicing the author’s opinion) into classifying sentiments. These publications, along with Turney’s contributions, kick-started a revolution of sorts in Natural Language Processing since growing language exchange on the web (social media, blogs, newsfeeds) was mined to understand people’s opinions.
Also commonly referred to as opinion mining, sentiment analysis was adopted by information giants like Thomson-Reuters who developed their inhouse NewsScope sentiment engine to measure news sentiment of thousands of companies for improved trading decisions.
By 2009, Google implemented changes to its search engine based on research papers and patents filed by them that explored the concept of aspect-based sentiment analysis to summarize reviews based on sentiment.
Soon in 2010, Twitter feeds were analyzed to gauge public opinion during the British elections, an example being a company called Linguamtics that scrutinized over 130,000 Twitter accounts.
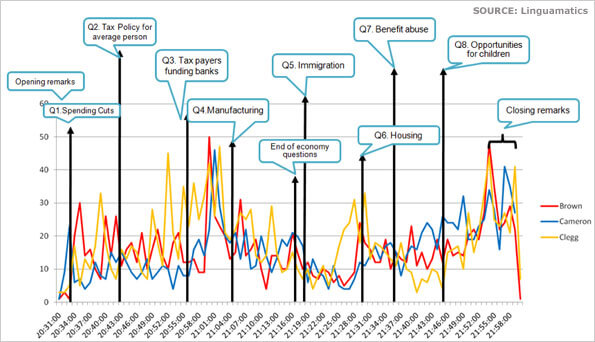
2010 British election tweets analysis
Though people were highly skeptical of the analysis and its outcomes, it got the tech world excited enough to try it out on the 2012 US Presidential elections as well. In 2015, it was reported that industry leaders like Intel and IBM used sentiment analysis to decipher their employees’ emotions.
Emoticons, sarcasm, and language complexities challenge the field of sentiment analysis, yet companies have started rapidly investing in understanding public sentiment to amplify customer experience and glean consumer insights.
So where’s NLP heading to these days?
Apart from the major applications of NLP mentioned in this article, topic modeling, document summarization, and character recognition are a few other problems solved by natural language processing.
The current Natural Language Processing scenario is strongly dominated by Deep learning. Once driven by recurrent neural networks (RNN), deep learning-based NLP is now experimenting with Convolutional Neural Networks(CNN) that have been proved useful with sentiment analysis, question-answering systems, and machine translation to a certain extent. Deep learning models are also used to speed up or consolidate standard NLP tasks of POS tagging, parsing, and named-entity recognition.
Until transfer learning proves its stance, deep learning models require large data sets which we aggregate for you at Xtract.io. Xtract also offers other NLP-intensive solutions like sentiment analysis and document indexing.
As the excitement around NLP mounts, maybe a decade from now JARVIS could be a reality and you can go and save the world, perhaps.
This article was originally published on Hackernoon









2 Comments
Hello. This specific awesome article couldn’t end up being written much better! Studying this post reminds myself of my previous area mate. He always retained chatting about this. I actually will forward this internet site to him. Fairly specific he will have a new good read. Thank an individual for sharing.
Thank you for reading and sharing. We are ecstatic to learn that you liked the article.