
What if the greatest challenge to AI success isn’t processing power, algorithmic complexity, or even talent deficit? What if it’s something much more basic that most organizations entirely miss?
Here’s the shocking truth: 87% of AI initiatives never enter production, and of those that do enter production, just 23% hit their desired business effect. The villain is not what you would think. It’s not broken algorithms or inadequate computing resources; It is the foundation these systems are built on, their data.
Most specifically, it’s the lack of genuinely enriched data that takes raw information and turns it into smart, scalable fuel for AI workloads.
The distinction between AI systems that fail to scale and those that revolutionize entire organizations often hinges on the quality, completeness, and richness of the context in the underlying data. Rich data is not merely clean data; it’s smart data that has been augmented with extra context, vetted for accuracy, and formatted for maximum consumption by AI.
The scalable problem in modern AI workflows
Most AI initiatives begin small, starting with proof-of-concept projects that utilize limited datasets. However, when organizations try to expand these solutions across departments, geographies, or use cases, they face the harsh reality of data gaps. Incomplete customer profiles, outdated company info, missing behavioral signals, and scattered data sources create bottlenecks that stop AI systems from providing consistent value at scale.
Traditional data preparation methods fall short when handling the volume, speed, and variety of data needed for enterprise-scale AI. Manual data cleaning becomes an endless bottleneck, while simple data validation tools don’t capture the contextual details that AI models require to perform effectively in different scenarios.
Understanding AI data enrichment
AI data enrichment represents a fundamental shift from correcting errors to creating intelligence. It’s the process of systematically improving existing datasets by adding missing information, correcting inaccuracies, and enhancing records with contextual details using artificial intelligence technologies.
It extends well beyond simple data profiling or error detection. AI enrichment actively fills gaps, resolves inconsistencies, and adds context that transforms raw data into strategic assets. The process uses multiple AI techniques, including natural language processing, machine learning algorithms, and computer vision, to extract insights from both structured databases and unstructured content sources.
For enterprise AI workflows, this means turning incomplete customer records into detailed profiles that include demographic details, firmographic information, technographic insights, behavioral patterns, and predictive signals. Each data point becomes a basis for smarter automation, better decision-making, and more personalized customer experiences.

Overcoming traditional scalability barriers
Enriched data directly tackles the most common barriers to AI scalability:
Data silos: By standardizing and improving data across different business systems, enrichment breaks down silos that usually prevent AI solutions from expanding across organizational boundaries.
Inconsistent data quality: Automated enrichment maintains consistent data quality standards across all business units and use cases, reducing the manual effort that often limits AI scalability.
Context loss: As AI systems grow across different fields, they may lose the contextual details that made them effective initially. Enriched data keeps and standardizes this context, enabling wider use.
Integration complexity: Rich, well-structured data lowers the difficulty of integrating AI solutions with existing business processes, making it easier to scale successful implementations.
The scalability multiplier effect
Enriched data creates a multiplier effect for AI scalability in several critical ways:
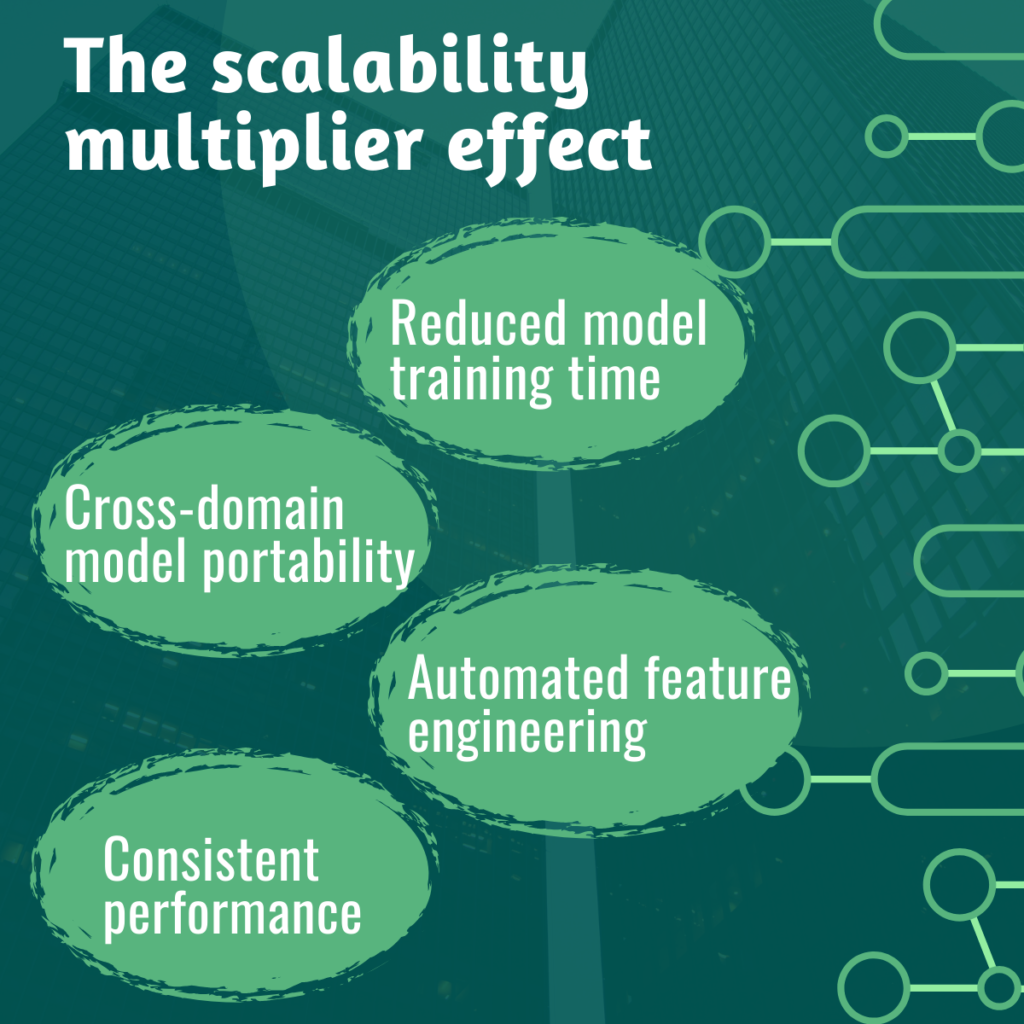
Reduced model training time: When AI models receive high-quality, contextually rich input data, they require fewer training iterations to achieve target performance levels. This dramatically reduces the time and computational resources needed to deploy AI solutions across new markets, products, or use cases.
Cross-domain model portability: Enriched datasets with standardized attributes and consistent formatting enable AI models trained in one domain to adapt more quickly to adjacent areas. A customer scoring model developed for the technology sector can more easily extend to professional services when both datasets share enriched firmographic and behavioral attributes.
Automated feature engineering: Rich, well-structured data enables automated feature engineering at scale. Instead of manually crafting features for each new AI application, enriched datasets provide the raw material for AI systems to automatically identify and generate relevant features for specific use cases.
Consistent performance across environments: Enriched data ensures that AI models maintain consistent performance as they scale across different business units, geographic regions, or customer segments. The additional context provided by enrichment helps models adapt to local variations while maintaining global consistency.
Technical architecture for scalable enrichment
Building scalable AI workflows requires a robust technical architecture that can handle enrichment at enterprise scale. This architecture typically includes several key components:
Real-time processing pipelines: Modern AI workflows demand real-time data enrichment capabilities. Streaming data architectures using advanced technologies enable continuous data enhancement as new information flows through business systems.
Microservices-based enrichment: Breaking enrichment processes into specialized microservices allows organizations to scale different types of enhancements independently. Demographic enrichment, sentiment analysis, and geolocation services can each scale based on demand while maintaining system reliability.
API-first integration: Scalable enrichment platforms expose enrichment capabilities through well-designed APIs, enabling seamless integration with existing business systems, third-party data sources, and AI/ML platforms.
Intelligent source orchestration: Advanced enrichment systems automatically identify and prioritize the best data sources for specific enrichment tasks, managing source reliability, cost, and latency to optimize overall workflow performance.
Building your enrichment strategy
Successfully implementing enriched data as the foundation for scalable AI workflows requires a strategic approach:
- Start with a comprehensive audit of current data sources and quality levels.
- Identify the gaps and inconsistencies that currently limit AI scalability in your organization.
- Prioritize enrichment efforts based on their potential impact on your most valuable AI use cases.
- Invest in automation tools that can handle enrichment, matching the velocity and capacity of your business. Manual enrichment processes will always be a limiting factor for AI scalability.
- Establish data governance frameworks that ensure enriched data maintains quality and compliance standards as it scales across different business contexts and regulatory environments.
Finally, design enrichment processes with future scalability in mind. Build systems that can adapt to new data sources, incorporate emerging AI techniques, and support use cases that don’t exist today.
Measuring enrichment impact on scalability
Organizations implementing data enrichment for scalable AI workflows should track specific metrics that demonstrate scalability improvements:
Time-to-value for new AI implementations: Measure how quickly new AI use cases can be deployed using enriched datasets compared to starting with raw data.
Model performance consistency: Track how AI model accuracy and performance metrics vary across different business contexts when using enriched versus non-enriched data.
Resource efficiency gains: Monitor the reduction in computational resources, manual effort, and time required to scale AI solutions when starting with enriched data foundations.
Cross-domain adaptation speed: Measure how quickly AI models can be adapted for new domains or use cases when trained on enriched versus standard datasets.
Building AI-ready data foundations with FreDa
As AI evolves from multimodal systems to real-time decision engines and autonomous workflows, enriched data becomes the backbone of scalable innovation. These advanced AI models rely on deep, contextual insights to deliver accurate, intelligent outcomes at scale.
With FreDa, you’re doing more than enriching data; you’re building a resilient AI-ready data asset. FreDa’s no-code platform empowers you to enrich, validate, and scale datasets instantly, without writing a single line of code, so your data stays trustworthy and future-ready.
Planning to leverage generative AI or LLMs? These systems need not just data, but richly structured data to perform effectively across diverse scenarios. By investing in FreDa today, you’re laying the groundwork for next-generation AI innovations. Today’s enrichment is tomorrow’s competitive advantage.
The real question isn’t if you should invest in data enrichment, it’s how fast you can deploy it. In a world where AI capabilities are democratizing rapidly, enriched data powered by FreDa is what sets forward-looking organizations apart.







