
Everyone talks about AI transformation as if it were a technology problem. It’s not. It’s a data problem. And the businesses winning aren’t the ones with the deep pockets; instead, they’re the ones who solved data preparation first. Here’s precisely why that matters more than anything else.
The real threat: How unprepared data kills digital dreams
Let us get straight to the point: we’ve all seen how digital transformation projects, initially full of promise and backed by significant investments, often lose momentum. These situations occur despite the idea being excellent, the research being thorough, and the execution path being clear. But why?
Here is the fact that could directly answer this question. About 80-90% of AI or automation projects fail due to poor data quality, rather than a lack of computational power or unclear algorithms.
If we take a moment to think about this deeply, we all will reach a common conclusion: bad quality data is the ultimate culprit. Even with a vast infrastructure setup, the most advanced AI models, competent AI technicians, and data scientists, poor data can significantly hinder the digital transformation process before it even begins. Hence, the first and foremost step to test the automation waters should be ensuring your data is thoroughly prepared to handle the AI initiatives ahead.
In other words, data preparation is the most wanted heads-up to any AI or automation project. But while you are exploring data preparation, your competitors might be climbing up the ladder in their automation pipelines, delivering insights, making informed decisions, and even capturing markets.
The data preparation imperative
So what exactly is data preparation, and why has it become so critical?
Data preparation is the process of cleansing, organizing, and standardizing raw datasets to support analysis, artificial intelligence, and business choices.
In the digital transformation context, data preparation involves:
- Cleaning inconsistent formats across different systems
- Standardizing naming conventions so everything speaks the same language
- Removing duplicates and errors that skew your insights
- Filling in missing values intelligently
- Merging data from various diverse sources into uniform datasets
- Ensuring data quality and reliability throughout the process
- Making data accessible in formats that analytics tools can actually use
Without proper data preparation, Digital transformation is just a grand design built on fragile foundations.
The hidden cost of bad data and poor data preparation methods
If you are still thinking of ignoring the quality of the data or its implications, let me present you with some numbers that might convince you otherwise.
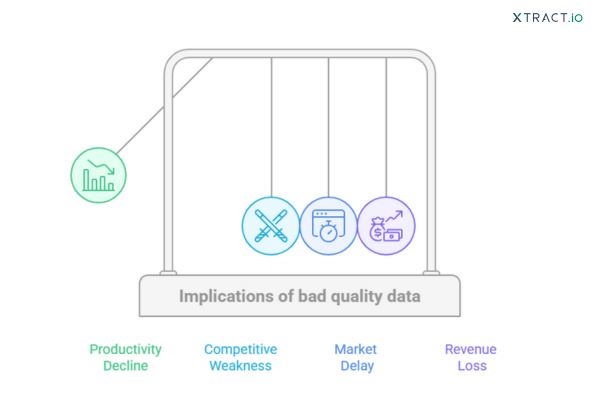
Impact on revenue: Having bad data can have a ripple effect on businesses, leading to less informed decisions, operational inefficiencies, and, most importantly, missed opportunities. Companies, on average, lose about $15 million annually solely because of data quality errors.
Losing competitive edge: Companies with poor data preparation methods often spend a significant amount of time correcting their data. In contrast, companies with proper data preparation modules are already in the advanced generation of AI model development.
Deteriorating productivity: Most employees spend about 80% of their time in data cleansing and formatting instead of delivering true business value.
Delayed time to market: Traditional or manual data preparation can delay automation initiatives by 6 to 12 months compared to automated data preparation modules.
But the most significant impact is the opportunity cost. If your data is unprepared, you might be missing out on subtle yet game-changing insights on customer signals, emerging market trends, upselling or cross-selling opportunities, or even regulatory risks. In simple terms, the longer you ignore your data quality, the farther you are from achieving your automation goals.
The challenges that are stopping you: why data prep is so hard
Now, the first question that pops out in your mind might be: “Okay, data preparation is important. How hard can it be?” Let’s uncover the challenges that are probably keeping your team up at night.

The sheer volume problem
Businesses of today’s age deal with massive volumes of data on a daily basis. Customer interactions, transaction records, sensor data, social media mentions, support tickets, it’s overwhelming. Manual data preparation simply can’t keep up with this volume.
The diversity nightmare
Your data doesn’t come in one neat format. Data comes in different orders, structured in databases, semi-structured in formats like JSON, and unstructured in emails, documents, images, and videos. Each type requires different preparation approaches.
The velocity challenge
Data keeps flowing in real-time. By the time you manually prepare last month’s data, this month’s data is already piling up, and next month’s decisions need to be made based on current information, not historical snapshots.
The quality chaos
Every data source has its own quality issues. Typos, inconsistent formats, missing fields, and duplicate records multiply as you add more data sources.
The integration problem
Getting data from different systems to work together is like trying to make people speaking other languages have a coherent conversation. Without proper preparation, your CRM data cannot communicate with your marketing automation platform, which in turn cannot interact with your customer service system.
The data diversity trend: great idea, bigger problems
With that aside, here’s something interesting that’s happening right now in the digital transformation space. Everyone’s talking about data diversity, the idea that you need varied, diverse data sources to make your AI models smarter and more accurate.
And they’re absolutely right! Diverse data does make for better AI. Instead of just analyzing sales numbers, you want to include customer feedback, market trends, operational metrics, social media sentiment, and behavioral data. The more diverse your data inputs, the smarter your AI becomes.
But here’s what the experts aren’t telling you: the more diverse your data sources become, the more unstructured data complexity you inherit.. This is the data diversity paradox: the more varied data you need for competitive AI, the more complex your data preparation becomes, and the further behind you fall if you’re trying to handle it manually.
Why manual data preparation is a terrible idea
Given everything we’ve discussed, you might think the solution is just to hire more people and throw more manual effort at the data preparation problem.
But here’s why manual data preparation is not just inefficient, it’s actively harmful to your transformation goals:
It’s impossibly slow
Your data science team spends 4/5 of their time on manual preparation tasks. That means your expensive experts are doing repetitive, tedious work instead of generating insights.
It doesn’t scale
Manual processes break down as data volume grows. You can hire more people, but coordination becomes a nightmare, and costs spiral out of control.
It’s error-prone
Humans make mistakes, especially with repetitive tasks. When you’re manually processing thousands of records, errors are inevitable. When these errors pile up in your AI models, they drive decisions based on misleading information.
It can’t handle diversity
Manual processes work okay for simple, structured data. But they completely fail when faced with the diverse, unstructured data sources that would actually make your AI competitive.
It creates bottlenecks
Every new data source requires new manual procedures. Your transformation speed is limited by how fast humans can learn and implement new preparation processes.
It’s not competitive
As you spend months on manual preparation, your competitors with automated systems are already in the market with data-driven products and services.
The brutal truth? Manual data preparation is akin to competing in modern manufacturing with hand tools, while competitors utilize automated factories.
Why automated data preparation changes everything
Automated data preparation doesn’t just speed up existing processes; it opens the door to entirely new ways of working. When data preparation happens automatically, you’re enabling:
- Automated systems can handle dozens of diverse data sources simultaneously, structured databases, unstructured documents, social media feeds, IoT sensors, and multimedia content, without breaking down under complexity.
- Instead of reports based on historical data, you get real-time insights as new information flows through your systems automatically.
- Want to test a new data source or try a different approach? With automation, you can experiment and iterate quickly, eliminating the need to spend weeks on manual setup.
- Your data preparation capabilities scale with your business growth and data volume without proportional increases in costs or complexity.
- While competitors struggle with manual processes, you’re already iterating on your next generation of data-driven innovations.
Meet your ultimate solution: XDAS
Handling unstructured data doesn’t need to feel daunting.. XDAS turns complexity into clarity, powering decisions with ease.
The unstructured data mastery: Remember that data diversity challenge we discussed? XDAS has been tackling exactly this problem for ages now. Twenty years of focused innovation in processing documents, extracting insights from text, handling multimedia content, and making sense of messy, unstructured data.
Intelligence that actually understands your data: XDAS doesn’t just move data around, it understands what it’s processing. Whether it’s a contract with unique formatting, a customer email expressing frustration, or a technical manual with embedded diagrams, XDAS applies the right processing approach automatically.
No-code power for business users: Your marketing manager can set up customer sentiment analysis from social media feeds. Your operations manager can automate maintenance report processing. Your finance team can extract key terms from thousands of contracts. All these are possible using XDAS that too in a completely code-free mode.
Continuous Learning and Adaptation: The more XDAS works with your specific data ecosystem, the smarter it gets. It learns your organization’s terminology, document formats, quality patterns, and business logic, continuously improving its processing accuracy.
Enterprise-Scale Performance: XDAS handles enterprise volumes of diverse data without performance degradation. Whether you’re processing thousands of customer emails or millions of sensor readings, the system maintains speed and accuracy.
The bottom line: Your transformation depends on this decision
Digital transformation isn’t just about adopting new technologies; it’s about enabling your organization to make better decisions faster using your complete data landscape. The longer you delay data preparation, the further your competitors race ahead.
Success in digital transformation isn’t about spending big on AI or dazzling with tech demos. They’re the ones that figured out how to turn their complete, diverse data ecosystem into a competitive advantage quickly and reliably.
Your digital transformation timeline doesn’t have to be measured in years, and your AI doesn’t have to be limited by incomplete data. With XDAS, companies are achieving complete data diversity and real-time insights in weeks, not months.
Ready to stop letting data preparation be your transformation bottleneck? Your transformation success depends on making this decision now, not later.
The reality is simple: unprepared data is actively costing you competitive ground every day. XDAS changes that equation.







