
If you were fascinated by the way DevOPs blew up the software industry and made a revolution, what is happening now might be great news to you. The data landscape is also going through a similar revolution, DataOps. And today, we’re living through the DataOps tipping point. What once felt experimental has become operationally unavoidable.
This DataOps moment isn’t just a gradual change; it happened because there is a radical upgrade to how we treat data. This momentary shift is shaped by the 3 key concepts listed below.
- AI maturity: Your models are hungry, and they need reliable, high-quality data feeding them continuously.
- Speed demands: Time-to-insight is everything. Manual processes no longer keep up.
- Data democratization: Everyone, from the data scientist to the sales manager, needs trusted data access.
The experts agree: over half of all enterprises will officially embrace DataOps by 2026.
The tipping point is here: Why DataOps is no longer optional
Forget the old data architecture built on silos and manual hand-offs. The modern enterprise, fueled by Generative AI, demands what we call operational rigor. Your data pipelines must be as robust, testable, and automated as your code pipelines.
- The AI imperative: If you’re serious about AI, you must be serious about DataOps. The quality, governance, and traceability of your training data are the biggest predictors of model success. DataOps moves this foundation from a chore to an industrial standard.
- A strategic game-changer: DataOps isn’t just for the engineering team; it’s elevating data from a back-office liability to a core business asset. Today’s market demands an always-evolving approach to the data lifecycle.
To handle this pressure, organizations need a new kind of data platform, one designed for collaboration, AI powered workflows, and continuous validation. The need is clear, because DataOps isn’t just another buzzword in the ever changing data landscape, it is a crucial turning point. To understand its impact, we need to break down what DataOps truly means and how it works on the ground.
What DataOps actually is
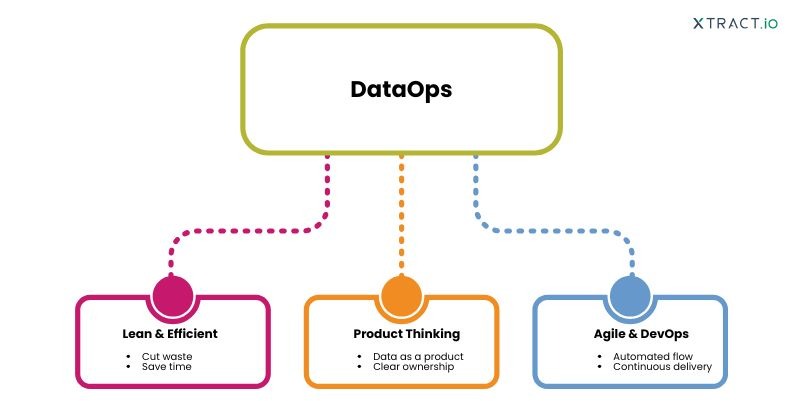
Think of DataOps as the ultimate mashup. It’s a collaborative practice that takes the best parts of:
- Lean: Cutting out wasted time and effort.
- Product thinking: Treating a dataset like a valuable product with an owner.
- Agile and DevOps: Automating the flow and ensuring continuous, rapid deployment.
The mission of Data Ops is simple: to boost the agility, speed, and quality of your insights by focusing on eliminating friction and orchestrating seamless hand-offs between data producers and data consumers.
What DataOps actually solves
DataOps emerged because the old ways were failing. When these roadblocks keep appearing, it’s a sign to rethink your approach.
- The clock is ticking: Your insights lose value fast, literally “with each tick of the clock.” DataOps ensures you can react and deliver analysis in near real-time.
- The data swamp: Ever struggled to find the right data across six different systems? DataOps dismantles those data silos and tackles the overwhelming complexity of today’s diverse data landscape.
- Waterfall woes: Say goodbye to fragmented, slow-moving teams and the traditional “waterfall” delivery model where processes were riddled with painful, manual bottlenecks. DataOps fosters true cross-functional alignment.
The goal is to stop spending time fighting fires and start spending time delivering strategic value.
The unstructured data bottleneck: The hidden killer of data agility
This is the point where the DataOps dream meets a harsh reality.We all agree on the promised outcomes of DataOps: improved productivity, iron-clad data trust, and a mindset shift of data self-service.
To achieve this vision, a future where data is a trusted product, every piece of data must flow seamlessly.
Time for the truth bomb
You can build the most beautiful DataOps pipeline imaginable, but it hits a wall when it meets unstructured data. And that data is everywhere:
- Industry research consistently shows that an estimated 80% of all enterprise data is unstructured. This means contracts, invoices, emails, images, and scanned reports.
- This content cannot be processed by a traditional ETL tool. It demands a human to read it, interpret it, and manually key it into a structured format.
But if you do unstructured data processing manually, it defeats the whole purpose of DataOps in the first place. If you are still think manual data processing is a better approach to unstructured data problem:
- Your automation game is at checkmate: The purpose of DataOps is creating zero touch pipelines, instead doing it manually can lead to high touch bottlenecks.
- Your speed advantage is at stake: Manual processing kills speed which makes the whole concept of real time data processing impossible.
- You cannot expect 100% reliability: As a known fact, manual processes have a higher probability of errors, which will ultimately affect the data quality. In other words it can lead to compromising trust, governance and compliance.
If you don’t solve this unstructured data problem, your DataOps strategy is guaranteed to stall.
The XDAS advantage: Building a unified DataOps engine
The only way to achieve true data agility is to apply AI directly to the problem of unstructured chaos. And how can we achieve that? By leveraging a comprehensive data processing platform that can turn diverse data into structured, more precisely DataOps ready assets.
With XDAS, you can achieve your seamless DataOps environment by processing the difficult 80% of your data, because we are exactly specialized in solving the unstructured data problem.
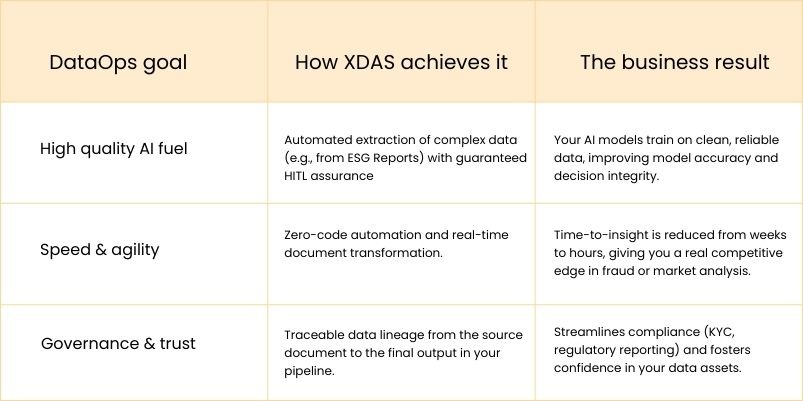
Automation that serves: XDAS elevates the automation game by exercising its sophisticated Intelligent Document Processing capabilities powered with Natural Language Processing (NLP) and GenAI to classify and extract even the complex attributes such as the line items from an invoices, contracts etc)
Compliance you can rely on: Most businesses shy away from automation in case of critical processes, because the chances of ending with bad data is high. Keeping that in mind, XDAS is built with human in the loop validation checks at every crucial step to ensure data reliability and compliance. This way XDAS fuels your AI models by incorporating human intelligence into your workflows guaranteeing data accuracy.
Assured business value: As XDAS solves the most important unstructured data bottleneck, you can ensure a frictionless flow of data throughout the data lifecycle. Having a smoother upstream process can positively impact your value proposition of converting raw data into actionable insights, thereby increasing your ROI.
Real-world impact: Turning liability into asset
Your DataOps transformation starts today
The 2026 DataOps Tipping Point is a strategic call to action for every enterprise leader. You are being asked to build an agile, scalable, and trustworthy data organization. But remember the crucial lesson: you cannot build an agile process on top of a static, manual bottleneck. Don’t let the unstructured chaos define your DataOps journey. Take control of the source.
Ready to transform your most complex documents into continuous, high-quality data streams? Talk to the Xtract.io team today.








